


MLOps in Practice — De-constructing an ML Solution Architecture into 10 components
A comprehensive introduction to the 10 key components of an end-to-end ML solution

👋 Hi folks, thanks for reading my newsletter! My name is Yunna Wei, and I write about modern data stack, MLOps implementation patterns and data engineering best practices. The purpose of this newsletter is to help organizations select and build an efficient Data+AI stack with real-world experiences and insights and assist individuals to build their data and AI career journey with deep-dive tutorials and guidance; Please consider subscribing if you haven’t already, reach out on LinkedIn if you ever want to connect!
In my previous blogs, I have talked about the three key pipelines (1) Data and Feature Engineering Pipelines, (2) ML Model Training and Re-training Pipelines, (3) ML Model Inference and Serving Pipelines, as well as the required underlying infrastructure in order to build a reliable and scalable MLOps solution. You can find the blog details here:
Learn the Core of Data Engineering — Building Data Pipelines
Learn the Core of MLOps — Building Machine Learning (ML) Pipelines
The Most Fundamental Layer of MLOps — Required Infrastructure
From this blog onwards, I will focus on explaining the detailed implementation of an end-to-end MLOps solution, to provide you with a practical playbook to refer to when you design and implement ML driven systems for your organizations. This implementation playbook includes a generally applicable ML solution architecture, a deep-dive into each of the key architecture components, as well as best practices for productionizing ML-driven systems.
Let’s start by explaining what a generically applicable ML solution architecture looks like.

A Generically Applicable ML Solution Architecture
An ML solution architecture describes the blueprint of what a solution should look like in high-level, and the key components required in order to build a scalable and reliable ML-driven system. When I say a generically applicable ML solution architecture, I mean this architecture can be applied to most ML-driven systems or use cases. From a ML lifecycle point view, this general architecture covers the key ML stages, from developing your ML models, to deploying your training systems and serving systems to production. You may need to customize some of them, however the overall workflow should remain roughly the same.
The following image depicts the key architecture components of an end-to-end MLOps solution. In total, there are 10 key components and below is a highlight summary for each of them.
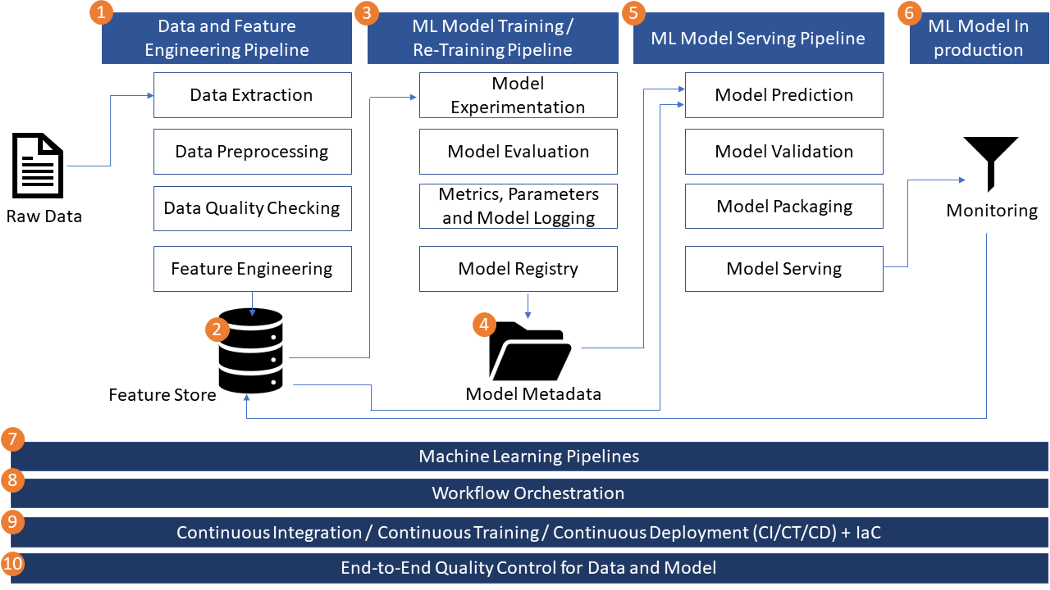
Data and Feature Engineering Pipeline — Deliver high-quality data in the time that the solution requires and produce useful ML features in a scalable and flexible way. Generally data pipelines can be separate from featuring engineering pipelines. Data pipelines refer to Extract, Transform and Load (ETL) pipelines where data engineers are responsible for delivering the data into a storage location such as a data lake built on top of S3 bucket, where feature engineering pipelines can start from. Feature engineering pipelines focus on converting raw data into ML features that can assist the ML algorithms to learn faster and more accurately. There are generally 2 stages involved in feature engineering. At the first stage, feature engineering logics are generally created by data scientists during development stages through various experiments in order to find the best suites of features, while data engineers or ML engineers are responsible for the productionisation of the feature engineering pipelines to deliver high-quality features for both model training and serving in a production environment.
Feature Store — Store and version curated ML features for discovery, sharing and reuse, as well as provide consistent data and ML features for model training and serving, which improves reliability of a ML-driven system. Feature store is the storage solution for persisting ML features created by the feature engineering pipelines. Feature store enables both model training and serving. Therefore it is a very important piece, an important architectural component for an end-to-end ML solution.
ML Model Training and Re-Training Pipeline — Experiment ML training runs with different parameters and hyperparameters in a easy and configurable way and log these training runs with rich parameters and model performance metrics. Automatically evaluate, validate, select and log the best-performing models to the ML model repository.
Training and Model Metastore — Store and record artifacts of ML runs, including parameters, metrics, codes, notebooks, results of configurations and trained models and provide functions like model lifecycle management, model annotation, model discovery and model re-use. For a comprehensive ML solution, there could be large amount of metadata generated from data and featuring engineering, model training to model serving. All this metadata is very useful for gaining more visibility into how the system works, providing traceability from data -> features -> models -> serving endpoints and useful information for debugging when the model stops working.
ML Model Serving Pipeline — Provision appropriate infrastructure for using a ML model in a production environment in light of both serving throughout, and latency. In general, there are 3 types of model serving — batching serving, streaming serving and online serving. Each serving type requires totally different infrastructure. Additionally the infrastructure should be fault-tolerant and auto-scalable to respond to requests and throughput fluctuations, particularly for business critical ML-driven systems.
Monitoring ML Model in Production — Provide data collection, monitoring, analysis, visualization and notification functions when there are data and model drifting and abnormalities detected, and assist system debugging with necessary information.
Machine Learning Pipelines — Compared to ad-hoc ML workflows, an ML pipeline provides a reusable framework that allows data scientists to develop and iterate faster, while keeping high-quality codes and reducing time to production. Some ML pipeline frameworks also provide orchestration and infrastructure abstraction functions
Workflow Orchestration — Integrate all the key components of an end-to-end ML driven system. Orchestrate and manage the dependencies of all these key components. Workflow orchestration tools also provide capabilities like logging, caching, debugging and re-tries.
Continuous Integration / Continuous Training / Continuous Deployment (CI/CT/CD) — Continuously test and integrate code changes, continuously train new models with new data and upgrade model performance when required and continuously serve and deploy models to a production environment in a safe, agile and automated way.
End-to-End Quality Control for Data and Model — Embed robust data quality checks, model quality checks, data and concept drifting detection at various stages of the end-to-end ML workflow, to make sure the ML solution itself is reliable and trustworthy. These quality control checks on descriptive statistics, the overall data shape, missing data, duplicates, constant (or almost constant) features, statistical tests, distance metrics and quality of model predictions.
Summary
These are the 10 components of a generically applicable solution architecture. By now, you should have a high-level understanding of what a ML-driven solution should look like. In future articles, I will dive into each component and specifically talk about :
What each component does and why is this component necessary
The key design considerations for each component
The tools, frameworks and services that can be leveraged for implementing each component
Please feel free to subscribe to my newsletter if you want to be notified when these articles are published. I generally publish 1 or 2 articles on data and AI every week.