


Build low-latency and scalable ML model prediction pipelines using Spark Structured Streaming and MLflow
MLOps in practice series — sharing design and implementation patterns of critical MLOps component.

To make ML models work in a real production environment, one of the most critical steps is to deploy the trained models for predictions. Model deployment (release) is a process that enables you to integrate trained ML models into production to make decisions on real-world data. When it comes to model deployment, there are generally two types:
One is batch prediction where the trained models are called and fed with a batch of data at a certain interval (such as once per day or once per week depending on how the models are used in certain business contexts), to periodically generate predictions for use.
The other is online prediction where a trained model is packaged as a REST API or a containerized microservice, and the model returns prediction results (generally in JSON format) by responding to an API request. With online prediction, the model makes predictions in real-time, meaning, as soon as the API is called, a model prediction result will be returned. Additionally the model REST API is generally integrated as part of a web application for end users or downstream applications to interact with.
However, between batch prediction and online prediction, we have seen an increasing number of scenarios where the model is not required to be packaged as a REST API, but the required latency for model prediction is quite low. Therefore, in order to solve the needs of these scenarios, I would like to share a solution — building low-latency and scalable ML model prediction pipeline using Spark Structured Streaming and MLflow.
The content of today’s article is:
A quick introduction to Spark Structured Streaming and mlflow;
Key architecture components of a low-latency and scalable ML prediction pipelines;
Implementation details of using Spark Structured Streaming and mlflow to build a low-latency and scalable ML prediction pipelines;
Let’s get started!

Introduction to Spark Structured Streaming and mlflow
Spark Structured Streaming — Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. Internally, by default, Structured Streaming queries are processed using a micro-batch processing engine, which processes data streams as a series of small batch jobs thereby achieving end-to-end latencies as low as 100 milliseconds and exactly-once fault-tolerance guarantees.
MLflow — MLflow is an open source platform for managing the end-to-end machine learning lifecycle.
Tracking — The MLflow tracking component is an API and UI for logging parameters, code versions, metrics, and output files, when running your machine learning code and for later visualizing the results.
Models — An MLflow model is a standard format for packaging machine learning models that can be used in a variety of downstream tools. The format defines a convention that lets you save a model in different “flavors” that can be understood by different downstream tools. The built-in model flavors can be found here. It is worth mentioning that the python_function model flavor serves as a default model interface for MLflow Python models. Any MLflow Python model is expected to be loadable as a python_function model. In today’s demonstrated solution, we loaded the trained model as a python function. Additionally we also leveraged the model API calls of log_model() and load_model().
Model Registry — The MLflow model registry component is a centralized model store, set of APIs, and UI, to collaboratively manage the full lifecycle of an MLflow model. It provides model lineage (providing visibility and traceability of the trained ML model coming from the combination of the specific MLflow experiment, and run), model versioning, stage transitions (for example from staging to production), and annotations.
Projects — An MLflow project is a format for packaging data science code in a reusable and reproducible way, based primarily on conventions. Each project is simply a directory of files, or a Git repository, containing your code.
If you are interested in understanding more about Spark Structured Streaming, you can check out my other article specifically talking about how to build streaming data pipelines.
Now let’s deep dive into the key architecture components of building such a a low-latency and scalable ML prediction pipeline.
Key architecture components of a low-latency and scalable ML prediction pipeline
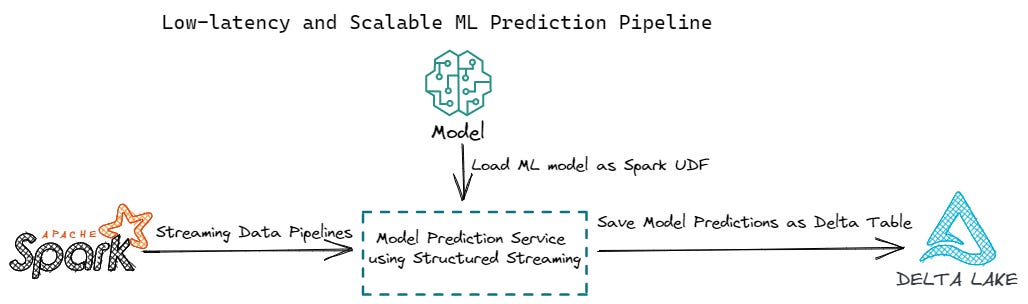
As shown in the above chart, there are 3 key architecture components in order to build a low-latency and scalable ML prediction pipeline:
The first step is to build a streaming data pipeline to ingest the raw data, convert the raw data into ML features and feed the ML features to the ML models in low latency;
The second step is to load the trained and registered ML model as a Spark User Defined Function (UDF) so that the model can make predictions in parallel, to leverage Spark’s distributed computing power. This is particularly useful when the data that is needed to make predictions is large in volume.
The third step is to save the model predictions results into a Delta table stored in a AWS S3 bucket. Then, the model prediction results can be used for downstream data consumers and applications. For example, you can build a Business Intelligence (BI) dashboard on top of the model prediction results to support business decision making. You can also build real-time monitoring mechanism to generate notifications and alerts based on model predictions to improve operation efficiencies.
Before we demonstrate the implementation of how to build a low-latency and scalable ML prediction pipeline, we need first to set some pre-requisites.
First and foremost is the schema of the trained model, as shown in the file below:
{"model_purpose" : "predicts the quality of wine using wine attributes",
"model_flavor" : ["python_function","sklearn"],
# The python_function model flavor serves as a default model interface for MLflow Python models.
# Any MLflow Python model is expected to be loadable as a python_function model.
# This enables other MLflow tools to work with any python model regardless of
# which persistence module or framework was used to produce the model.
"model_algorithm" : "sklearn.linear_model.ElasticNet",
{"model_signature" :
"model_input_schema":[
{"name": "fixed acidity", "type": "string"},
{"name": "volatile acidity", "type": "string"},
{"name": "citric acid", "type": "string"},
{"name": "residual sugar", "type": "string"},
{"name": "chlorides", "type": "string"},
{"name": "free sulfur dioxide", "type": "string"},
{"name": "total sulfur dioxide", "type": "string"},
{"name": "density", "type": "string"},
{"name": "pH", "type": "string"},
{"name": "sulphates", "type": "string"},
{"name": "alcohol", "type": "string"}],
"model_output_schema" [
{"type": "tensor", "tensor-spec": {"dtype": "float64", "shape": [-1]}}
]
},
"model_registry_location" : "runs:/<RUN_ID>/<MODEL_NAME>",
# If you are using mlflow to manage the lifecycle of your models,
# the model is loggged as an artifact in the current run using MLflow Tracking
"model_stage" : "Production",
# With mlflow, you can transition a registered model to one of the stages:
# Staging, Production or Archived.
# In the demo of this article, the model is alreay transitioned to the "production" stage.
"model_owner" : "<MODEL_OWNER_EMAIL/MODEL_OWNER_GROUP_EMAIL>"
}Second is the schema of the training and test data. Making sure the schema of data fed to the model matches with the model input schema is critical to avoid any errors caused by a schema mismatch during model prediction. The data schema is shown as below:
StructType([
StructField('fixed acidity', StringType(), True),
StructField('volatile acidity', StringType(), True),
StructField('citric acid', StringType(), True),
StructField('residual sugar', StringType(), True),
StructField('chlorides', StringType(), True),
StructField('free sulfur dioxide', StringType(), True),
StructField('total sulfur dioxide', StringType(), True),
StructField('density', StringType(), True),
StructField('pH', StringType(), True),
StructField('sulphates', StringType(), True),
StructField('alcohol', StringType(), True),
StructField('quality', StringType(), True)
])The data used in this article is from here. Feel free to find out more details about the data.
Now we have a good understanding of what the model schema and data schema looks like, we can start implementing the ML prediction pipeline using Spark Structured Streaming and MLflow. The complete solution is explained in detail in the next section.
The complete solution — building a low-latency and scalable ML prediction pipeline using Spark Structured Streaming and MLflow
Step 1 — Build a streaming data ingestion pipeline to load the data for prediction in low-latency. Structured streaming allows you to define how fast the data needs to be processed by setting a micro-batch interval. In today’s demo, we will set the micro-batch interval as 5 minutes, meaning, every 5 minutes, the streaming pipeline will pull raw data and call the deployed ML model for predictions. Below is a sample streaming data ingestion pipeline to load the raw data (in CSV format) into a Spark streaming data frame.
streamingDF = (spark
.readStream
.option("sep",",")
.option("header", "True")
.option("enforceSchema", "True")
.schema(csvSchema)
.csv(<YOUR-CSV-DATA-LOCATION>))Step 2 — Load the registered model as a Spark User Defined Function (UDF) function.
import mlflow
logged_model = 'runs:/<RUN_ID>/<MODEL_NAME>'
# Load model as a Spark UDF.
# Override result_type if the model does not return double values.
loaded_model = mlflow.pyfunc.spark_udf(spark, model_uri=logged_model, result_type='double')Step 3 — Make predictions on the streaming data frame and save the ML model predictions results into a Delta table for downstream consumers.
# Predict on a Spark DataFrame.
from pyspark.sql.functions import struct, col
streamingDF.withColumn('predictions', loaded_model(struct(*map(col, streamingDF.columns))))The Complete Solution
import mlflow
from pyspark.sql.functions import struct, col
from pyspark.sql.types import StructTypelogged_model = 'runs:/<RUN_ID>/<MODEL_NAME>'
loaded_model = mlflow.pyfunc.spark_udf(spark, model_uri=logged_model, result_type='double')
checkpointLocation = <STREAMING_CHECKPOINT_LOCATION>
deltaLocation = <PREDICTION_STORAGE_LOCATION>streamingDF = (spark
.readStream
.option("sep",",")
.option("header", "True")
.option("enforceSchema", "True")
.schema(csvSchema)
.csv(<YOUR-CSV-DATA-LOCATION>)
.withColumn('predictions', loaded_model(struct(*map(col, streamingDF.columns)))))(streamingDF.writeStream
.format("delta")
.outputMode("append") # .outputMode("complete"), .outputMode("update")
.option("checkpointLocation",checkpointLocation)
.option("path", deltaLocation)
.trigger(processingTime='5 minutes') # trigger(availableNow=True), .trigger(once=True), .trigger(continuous='1 second')
.queryName("streaming csv files")
.start())Summary
Thanks for reading today’s article. Hopefully you can leverage this model deployment pattern in your ML-driven applications.
In my previous article, MLOps in Practice — De-constructing an ML Solution Architecture into 10 components, I break down an end to end ML solution architecture into 10 components. Today’s article focuses on explaining one of the popular patterns for the component of building ML serving pipelines.
I will continue to share articles on MLOps in practice series to explain the design and implementation patterns of critical MLOps components.
Please feel free to subscribe if you want to be notified when these articles are published. I generally publish 1 or 2 articles on data and AI every week.